Red Hat Connected Vehicle Architecture
Architecture
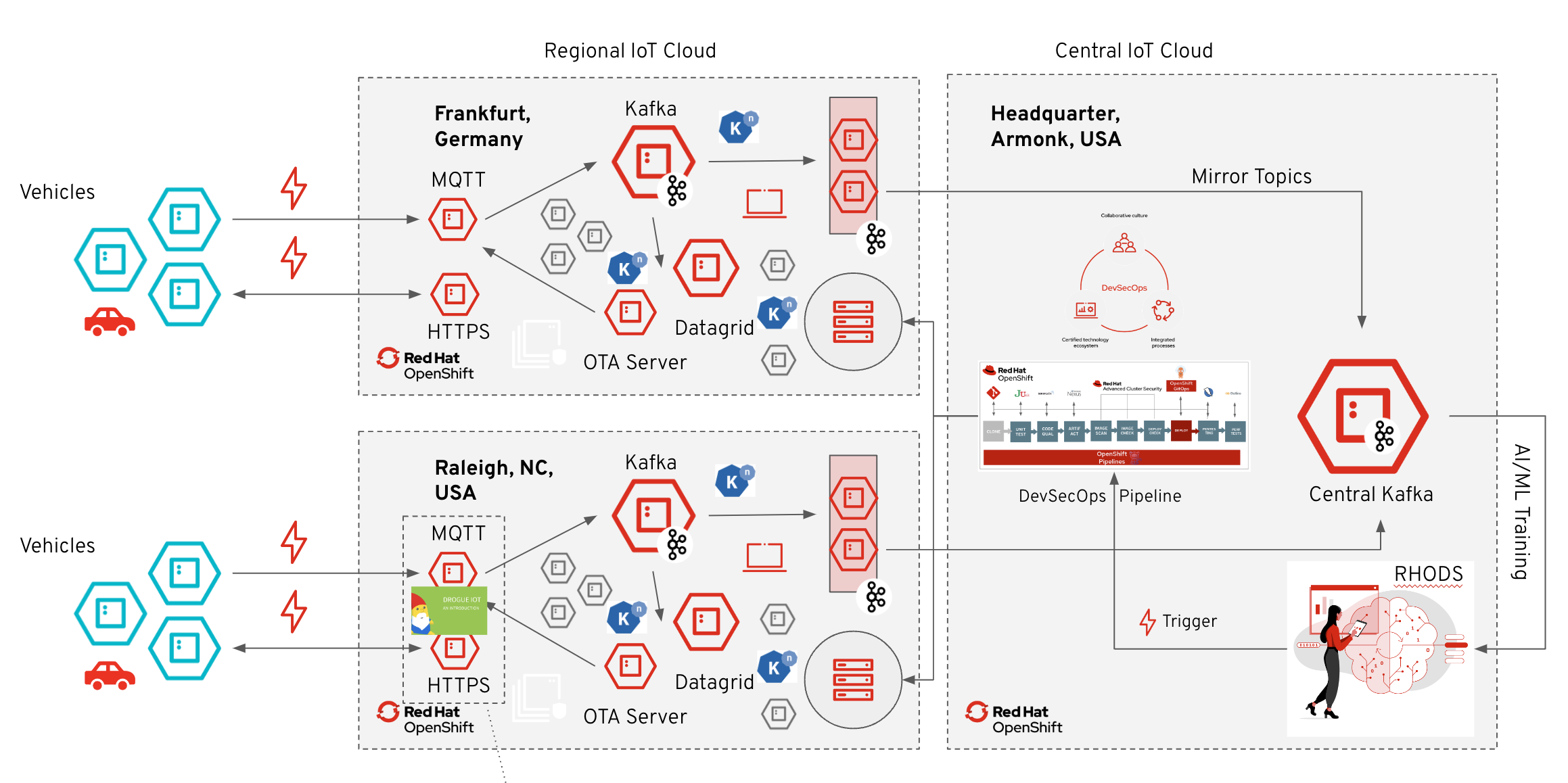
1. Core Concepts
From a technical perspective, the solution pattern has two core elements: Connected Vehicles and Connected Vehicles Zones.
Connected Vehicles:
The vehicle simulators are implemented in Quarkus (cloud-native Java stack) that simulate vehicles (connected cars) and send telemetry data to a regional IoT cloud backend. In this demo they represent the vehicle edge.
Connected Vehicles Zone:
A Connected Vehicles Zone represents a configuration for a specific location, e.g. an environmental zone for which a maximum CO2 emission has been defined. Or a listing of various mobility services that are available at this location. The Connected Vehicles zones are implemented as a Kubernetes Custom Resource.
For each simulated vehicle, a route is initially randomly selected from a pool of routes. Driving this route from start to destination is simulated and the current position data as well as current telemetry data such as speed, RPM, CO2 emissions… are sent over the Drogue.io connectivity stack to a regional IoT cloud backend infrastructure. This is done by streaming all sensor data from the vehicles to local Kafka clusters.
2. Drogue.io connectivity stack
The Drogue IoT cloud components provide a connectivity layer between the edge and the cloud. Devices, cars in the case, are being registered with the device registry, storing credentials and configuration. Devices can also act as a gateway towards the cloud. Multiple local sub-devices can access the cloud through that gateway device. These don’t need to be physical devices, but could also be different applications/containers.

Data can come in through either MQTT (v3, v5), CoAP, HTTP, or a custom provided protocol adapter. The actual payload is not processed, but passed along as a CloudEvent to the consuming application, which can again consume it via Kafka, MQTT, WebSocket, or Serverless APIs. In the middle the incoming telemetry is buffered in Kafka, so that consuming applications can be scaled and process a backlog when necessary.
Commands (cloud-to-device messages) flow back the same path.

Part of the telemetry data are connectivity events, which allow to deduct if a device is currently connected to the system. This allows the consuming applications to trigger actions, like sending commands or initiating things like updates.
The device registry is designed in a way that it can integrate with external device management systems. For example, it is possible to reconcile the device configuration with an external management system. This can be achieved by creating a custom, operator-style process.
3. Cloud side processing
Apache Kafka is the central system for all incoming data. The incoming data is made available via web socket to a real-time dashboard for visualization and is also updated in a distributed in-memory cache. This means that the last status of the entire IoT system can be retrieved from the cache at any time.
The cloud-native integration framework Apache Camel-K was used to integrate the systems involved. Specifically, the integration of MQTT into Kafka, the integration of Kafka into the cache as well as the websocket endpoints and the cache REST API have been implemented.
When vehicles enter or leave a Bobbycar Zone, a Zone Change Event is triggered. This event is made available to the respective vehicle as an MQTT message and is also used in the form of a cloud event to trigger an over-the-air update by calling serverless services/functions.
The updated zone configuration is not pushed into the vehicles, but rather the vehicles obtain the current configuration via the cache API after a zone change event.
By using Kafka Mirror Maker, the incoming data from the regional Kafka clusters is transferred to the Kafka clusters in the central IoT cloud in order to persist an aggregated status across all locations and, for example, to carry out stream analytics on this basis. Furthermore, the relevant data from the regional Kafka clusters is stored in an S3 compatible data lake in the central IoT cloud, and is then used for machine learning with, for example, Red Hat OpenShift AI.
5. Technology Stack
-
-
OpenShift Serverless
-
OpenShift Pipelines
-
-
Red Hat Application Foundation
-
AMQ Streams
-
AMQ Broker
-
Apache Camel-K
-
Datagrid
-
Other:
-
Angular